 |
Gregory Davies
Tandem Computers
Cupertino, CA
Norman Matloff
Department of Computer Science
University of California at Davis
PVM, a message-passing software system for parallel processing, is used on a wide variety of processor platforms, but this portability restricts execution speed. The work here will address this problem mainly in the context of Ethernet-based systems, proposing two PVM enhancements for such systems.
The first enhancement exploits the fact that an Ethernet has broadcast capability. Since unenhanced PVM must, to keep portability, avoid using broadcast, execution speed is sacrificed. In addition, the larger the system, the larger the sacrifice in speed. A solution to this problem is presented.
The second enhancement is intended for use in applications in which many concurrent tasks finish at the same time, and thus simultaneously try to transmit to a master process. On an Ethernet, this produces excessively long random backoffs, reducing program speed. An enhancement, termed ``programmed backoff,'' is proposed.
PVM [3] is a general-purpose message-passing environment for parallel processing. Though it is used on a wide variety of multiprocessor and multiple-processor platforms, this portability restricts execution speed. Our goal here is to address that problem in the context of Ethernet-based systems, presenting two PVM enhancements for such systems.
The first enhancement, discussed in Section 2, exploits the fact that an Ethernet has broadcast capability. Since unenhanced PVM must, to keep portability, avoid using broadcast, execution speed is sacrificed. The pvm_mcast() function must transmit separate messages to each of the intended recipients, which is quite wasteful on a broadcast channel such as Ethernet. And most importantly, the larger the system, i.e. the greater the number of processors, the larger the sacrifice in speed. A solution to this problem is presented here.
Also, a similar PVM modification for hypercube systems is outlined. Though such systems are not inherently of a broadcast nature, broadcast algorithms do exist, and we show how they can be exploited in PVM.
The second enhancement, developed in Section 3, is more subtle. It is intended for use in settings in which task time has a small statistical coefficient of variation. In such applications, which have been shown to be quite common [1], many concurrent tasks will finish at (almost) the same time, and thus will simultaneously try to transmit to a master process. Unless the nodes are physically distant from each other, it is not likely that a collision will then occur. Instead, one node will successfully transmit, and the Ethernet hardware at the other nodes will sense that the channel is busy and wait to transmit. If the wait is excessively long, packet timeouts and retransmissions within PVM can reduce program speed. Our enhancement here, which we call programmed backoff, makes the process under which slave tasks transmit to the master more orderly, so that their attempts to send succeed on the first try, thus avoiding delay.
Due to portability considerations, the PVM pvm_send() function cannot be used for broadcast. If in a given application we wish to send the same message to all tasks, or a group of tasks, pvm_mcast() must be invoked to send separately to each task. In a broadcast channel such as Ethernet,1 this represents a missed opportunity for enhanced program speed, and broadcast can be improved by tailoring to other specific interconnect topologies as well.
The pvm_send() function is quite complex, and a great deal of modification would have to be done in order to add broadcast capability. Thus, as a first step to demonstrate the potential of such an enhancement, we instead added broadcast capability to PVM's pvm_barrier() function.
The broadcast is done at the socket level, using Unix calls such as socket() and setsockopt() [5].
In unmodified PVM, the barrier-done notification works as follows: When the group server has received the appropriate number of barrier messages from PVM tasks, it uses pvm_mcast() to notify each remote machine. The pvm_mcast() routine first allocates a ``multicast address" to represent the list of PVM task IDs involved in the barrier, then sends a packet containing the multicast address and list of IDs to each machine. After that the barrier message is sent to each machine on the list using the multicast address as the destination.
Adding broadcast messages to PVM thus required making changes to both the PVM daemon and PVM group server code. The code which actually sends the barrier message resides in the group server, and existing group server routines needed to be modified to handle both the broadcast and non-broadcast cases. This includes code which, upon startup of the server, creates a socket which is dedicated to sending broadcast messages. Added to the list of library functions was a pvm_lanbarr() call, to enable users to specify that a barrier should use broadcast.
Changes to the PVM daemon require a little more explanation. When the daemon is first started, it executes code to process command-line options, initialize sockets, start slave PVM daemons on other machines, and initialize data structures. After startup the daemon enters an infinite for loop where each of the sockets (one for messages from the network, one for messages from local processes) is repeatedly checked for activity and, if a message is found, support routines are called to process the message. Processing consists of reading the message header, sending acknowledgements, and routing messages to the appropriate destination.
In order to receive broadcasts from the group server, a new socket was added which listens for broadcast messages on the appropriate port. An FFBCAST flag in the PVM packet header allows the message processing routines to distinguish broadcasts from other messages. The message is read and a copy of the packet is queued to be sent to each of the local tasks whose ID is specified in the message body. The PVM daemon regularly checks for messages waiting to be sent to local processes, and at that point the barrier packets are sent out.
Local processes receive messages by use of the pvm_recv() library function, which calls routines to read messages from the PVM daemon using a socket. Because PVM messages may be larger than the maximum size of a UDP packet, PVM has facilities for fragmenting messages into separate packets to be sent out and for reconstructing a message when it is received. Since broadcast barrier messages are at most one UDP packet in length, the fragmentation routines are bypassed.
The first test was a comparison between the broadcast and standard barriers using a simple dummy-barrier program. The program consists of a set of ``slave" processes which run a dummy for loop and then make a barrier call, and a master process which spawns one slave process on each of N machines. Timing information was collected by placing gettimeofday() system calls before and after the barrier and is accurate to the 3.9 millisecond resolution of the DECstation system clock.
In order to fully test the benefits of the broadcast barrier proposed here, the arrival of processors at the barrier should be nearly simultaneous. Since the master process spawns the slaves one after another and each process takes an average of 100ms to start, the processes begin at different times and therefore must be synchronized in order to arrive at the barrier at the same time. To accomplish this an initial broadcast barrier call was added before the dummy loop, and timing data was collected on the (second) barrier call after the loop. Processes are synchronized by the first barrier because they receive the group server's broadcast message at the same time (in fact, without broadcast capability such synchronization cannot be done).
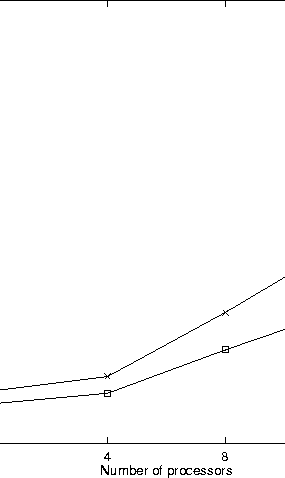
Figure 1 is a plot of execution times for the standard PVM barrier and our proposed broadcast barrier, for a number of machines ranging from 1 to 32. The broadcast barrier speeded the execution by an amount ranging from 24% for a single machine up to 36% for a group of 32 machines. The network was lightly loaded at the time of the experiments, so the observed speedups were primarily due to the fact that the group server incurs substantial system-level overhead each time it sends a message. For a 32-machine group, then, our broadcast barrier incurred this overhead only once, while the standard PVM barrier incurred it 32 times.
To verify this, the barrier execution times were recorded for each of 32 machines in a single run of the program using the standard PVM barrier. In ascending order, the times (in ms) were:
336, 402, 406, 410, 414, 418, 422, 422, 426, 430, 434, 438, 441, 441, 445, 449, 453, 453, 461, 465, 465, 469, 469, 477, 480, 480, 488, 496, 500, 500, 504, 512
The range of execution times reflects the fact that the different machines were waiting their turns to receive separate individual barrier messages from the group server. By contrast, similar data from 32-machine test runs using the broadcast barrier shows that the execution times, on the average, only varied by 13ms from highest to lowest. Again, the same effect should occur if routines like pvm_mcast() are replaced by true physical broadcasts of the type proposed here, with the effect being very large if, for instance, large data structures are being transmitted.
Again, these experiments were conducted on a dedicated network, i.e. no other users were on the network at the time. On a ``normal'' network with multiple users, the benefits would be even greater: sending only one message instead of N would mean risking only one delay due to traffic on the Ethernet (more on this later), rather than potentially N such events.
The improvement due to broadcasting was consistent over multiple runs of the test program.
Next, the broadcast barrier was tried on a real application, a root-finding program [2]. Here, a function f is known to have a single root in a given interval, which the program finds (to the desired level of accuracy) in a parallel iterative procedure. In any given iteration, the current interval to be searched is divided into N subintervals, where N is the total number of machines. Each slave inspects its assigned subinterval, and then reports to the master whether the given function has a sign change in that subinterval. Only one of these subintervals will experience such a change, and it will then become the new interval. The master will broadcast the values of the endpoints of the new interval to the slaves, so that they can divide it into new subintervals, and so on.
The function f used in our experiments was a fourth-degree polynomial. Since the evaluation of this function is very fast,2 successive barrier calls interfere with one another and cause a backlog of messages to build up at the PVM servers. In many cases the timing data showed that the performance of the barrier deteriorated with successive calls (see example in Table 1).
| 7| c | Iteration # | |||||||
| Machine | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| appert | 55 | 78 | 74 | 109 | 98 | 102 | 105 |
| archer | 39 | 62 | 74 | 109 | 98 | 102 | 105 |
| berliner | 51 | 86 | 86 | 117 | 102 | 98 | 105 |
| gramme | 62 | 125 | 141 | 113 | 129 | 129 | 105 |
| Mean | 52 | 88 | 94 | 112 | 105 | 107 | 105 |
Thus another PVM modification was made, in which the PVM source code insures that the group server and the master process reside on different machines. A comparison of the performance of the PVM standard and broadcast barriers, both under this modification, is given in Table 2.
| # of | ||
| processors | standard | broadcast |
| 4 | 78 | 65 |
| 12 | 385 | 351 |
It also should be noted that under each type of barrier, overall program execution time was cut nearly in half (data not shown) by this modification.
Though an Ethernet structure is inherently a broadcast channel, other topologies can also profitably use broadcasts, with not too much extra effort. Here we will outline how a PVM true broadcast capability could be implemented for hypercube systems.
Instead of doing a multicast in which a PVM task uses pvm_mcast() to transmit a separate instance of a message to each receiving node, we can have the task send only to the immediately adjacent nodes. These nodes can then relay the message to a minimal subset of their neighbors, and so on until all nodes of the hypercube have been notified. Algorithms for broadcast on a hypercube in which the message is forwarded in this manner exist (one example is in [4]) and can be shown to be optimal in various senses.
In discussing such algorithms, it is convenient to number the nodes in a hypercube using bit strings of length n, where n is the dimension of the hypercube (and n = log2 N, where N is the number of machines in the system). Adjacent nodes are numbered so that they differ from one another in only one bit position. We can define the i-th neighbor of a particular node as the node which differs in the i-th bit position.
Here is how the broadcast procedure in [4] could be implemented in PVM, illustrated for a specific application, root-finding. The function getnodenum() is assumed to return the physical node number of the processor which calls it. If such a function is not available, any numbering of the nodes will work (such as those given by PVM task ID), and the scheme shown here will still result in fewer messages than if PVM's standard broadcast function were used. However, under a nonphysical node numbering, nodes which are ``neighbors'' in the sense of differing in only one bit position will not necessarily be physically adjacent, and thus messages may need to travel further distances.
struct MsgStruct {
/* interval endpoints */
float LeftEnd,RightEnd;
/* routing bit string */
int C[CUBE_DIMENSION];
};
/* assume each process keeps a table
of PVM task ID vs. physical
node number */
int TaskTable[MAX_NODES];
void NextInterval(NodeNum)
int NodeNum;
{ int I, NItem, Dest;
struct MsgStruct Msg;
NItem =
sizeof(struct MsgStruct)/sizeof(char);
/* if master node, then initialize the
message */
if (NodeNum == MAX_NODE_NUM) {
FindNewIntvl(Msg); /* determine new
interval, based
on feedback
previously
obtained from
the processors */
for (I = 0; I < CUBE_DIMENSION; I++)
Msg.C[I] = 1;
}
/* otherwise, wait for the message */
else {
pvm_recv(-1,BCAST_NEW_INTVL);
pvm_upkbyte((char *) Msg,NItem,1);
}
/* Send copies of the message
as needed */
for (I = 0; I < CUBE_DIMENSION; I++)
if (Msg.C[I] == 1) {
Msg.C[I]= 0;
/* Given the physical node number
of this node, find the node number
of the Ith neighbor. */
Dest = FindIthNeighbor(NodeNum,I);
pvm_initsend(PvmDataDefault);
pvm_pkbyte((char *)Msg,NItem,1);
pvm_send(tasktable[Dest],
BCAST_NEW_INTERVAL);
}
}
void DoProcess()
{ int NodeNum;
NodeNum = getnodenum();
while (1) {
NextInterval(NodeNum);
CheckSubinterval(NodeNum);
}
}
In a situation where multiple stations on an Ethernet LAN are attempting to send large messages simultaneously, the resulting contention can increase the rate of collisions on the network. To minimize such contention, it can be useful to program a waiting period for each node which allows the messages to be sent one after another without overlap. A simple way to accomplish this is to assign each sending node a unique number n in the range 0 to N-1 (where N is the number of nodes). The waiting period can then be programmed as backoff= k*n, where k is a constant. By assigning an appropriate value of k based on information from trial runs of the application, contention can be reduced and the overall throughput of messages increased. Another potential benefit from such a backoff is that packet acknowledgements (as implemented by the PVM protocol) arrive sooner and the number of packets which are re-sent due to timeouts is decreased.
The master program in this test begins by spawning N slave processes, each on a different machine. The master then sends each slave (a) the total number of nodes and (b) its individual node number, which is assigned uniquely as described above. After receiving the node number, the slaves execute a broadcast barrier for synchronization. Each slave then sends a large message to the master, consisting of either 10,000 or 100,000 double-precision numbers (80,000 or 800,000 bytes). The Ethernet on which the test was done was relatively short and thus had few collisions, but the large size of the messages, along with the fact that the slaves are sending simultaneously, made this program an appropriate test of our programmed backoff procedure.
For comparison with the cases in which machines do not use programmed backoff and transmit simultaneously, programmed waits of kn milliseconds were used, where k is a constant and n is the node number of the slave process.
In order to get accurate timing data, the PVM group server and the master program were made to run on the same machine. Times were recorded immediately after the broadcast barrier message was sent out and again when the master program finished receiving the arrays from the slaves.
Results of these tests are presented in Table 3. For fewer than eight nodes, use of a programmed wait was of little benefit. For eight or more nodes, waiting produced a significant time savings. For 12, 16, and 24 nodes the savings ranged from 26% to 37%. Another observation is that the results were similar for array sizes of 10,000 and 100,000.
| # of | # of | array | average | |
| nodes | runs | wait(ms) | size | time(ms) |
| 1 | 4 | 10,000 | 466 | |
| 4 | 5 | 10,000 | 1375 | |
| 4 | 5 | 300*n | 10,000 | 1373 |
| 4 | 4 | 600*n | 10,000 | 2281 |
| 4 | 4 | 100,000 | 14532 | |
| 4 | 4 | 2000*n | 100,000 | 13530 |
| 8 | 4 | 10,000 | 2965 | |
| 8 | 4 | 300*n | 10,000 | 2714 |
| 12 | 4 | 10,000 | 6056 | |
| 12 | 4 | 300*n | 10,000 | 3844 |
| 16 | 4 | 10,000 | 7714 | |
| 16 | 4 | 150*n | 10,000 | 6577 |
| 16 | 4 | 300*n | 10,000 | 5118 |
| 16 | 4 | 100,000 | 75526 | |
| 16 | 4 | 2000*n | 100,000 | 55879 |
| 24 | 4 | 10,000 | 11006 | |
| 24 | 4 | 300*n | 10,000 | 8069 |
Although good results were achieved using a programmed wait, even in the cases where messages were sent simultaneously there were few if any collisions at the Ethernet level. This can be explained by the fact that the machines on the network used here were located in close enough proximity to one another that signal propagation delays are small. As an example, if two stations on an Ethernet are connected by 200 meters of wire, they must begin sending within 10 bit times of one another to cause a collision. The machines used for testing were generally less than 200 meters apart, and certainly did not approach the 2.5 km maximum separation allowed for Ethernet.
Instead, the time savings seem to result from the packet timeout mechanism discussed in the last subsection. Within PVM, a duplicate copy of a packet is sent if an acknowledgement for the first copy has not been received within a specified timeout period. A programmed wait reduces the contention between nodes, and therefore allows the data to be sent with fewer retries. It was verified that this was indeed happening, by modifying the source code in the PVM daemon to keep track of retransmitted packets. Using 12 nodes and an 80,000 byte message size, data was collected on packet retries for two runs with no programmed wait, and two runs with Wait = (300ms)*(Node number). The results showed substantially more retries (average of 12 without wait versus 2 per node with wait) when no wait was used.